METR
@metr.org
METR is a research nonprofit that builds evaluations to empirically test AI systems for capabilities that could threaten catastrophic harm to society.
Top posts

We ran a randomized controlled trial to see how much AI coding tools speed up experienced open-source developers. The results surprised us: Developers thought they were 20% faster with AI tools, but they were actually 19% slower when they had access to AI than when they didn't.
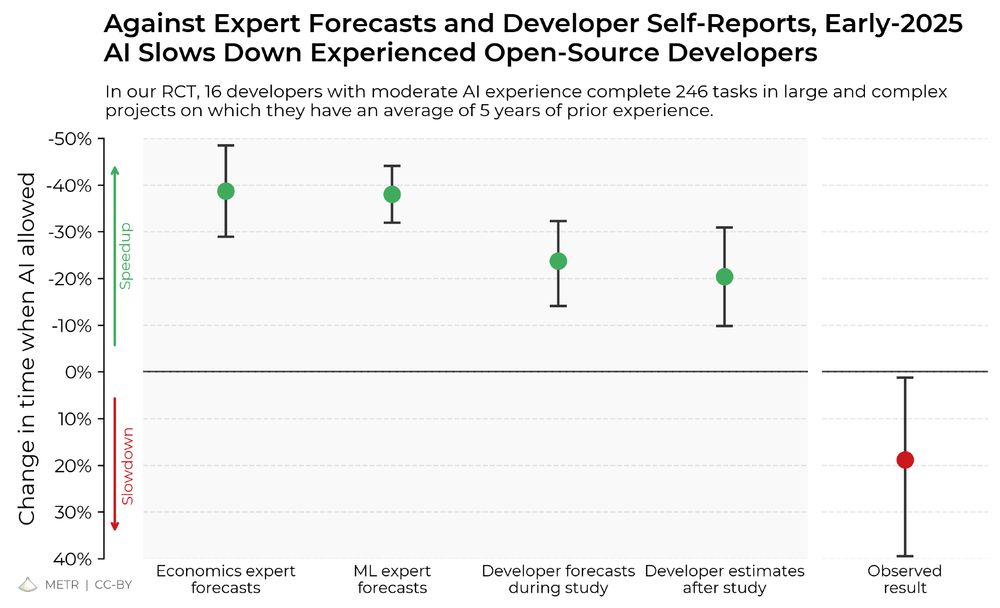
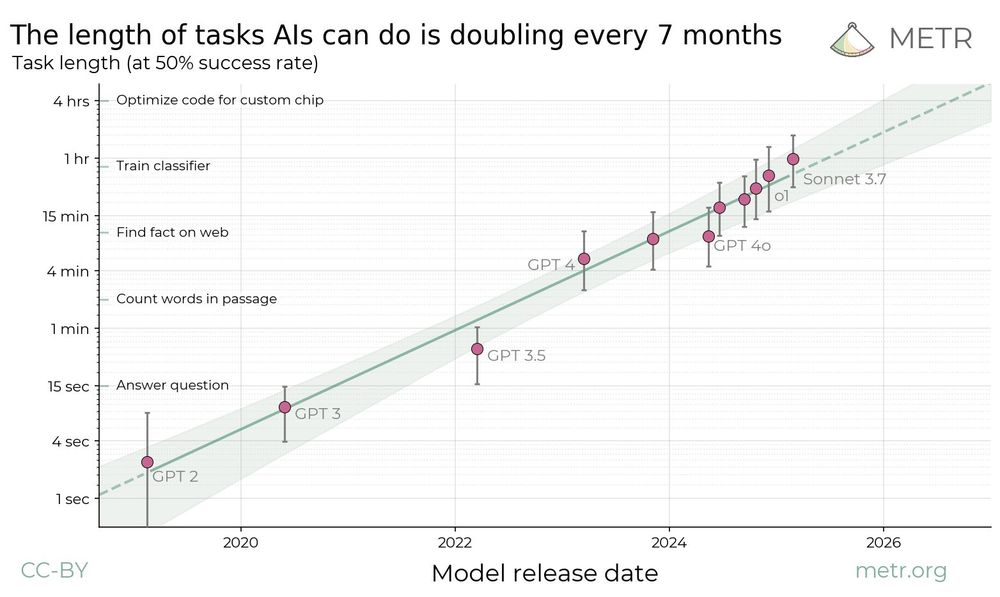
We have open-sourced anonymized data and core analysis code for our developer productivity RCT. The paper is also live on arXiv, with two new sections: One discussing alternative uncertainty estimation methods, and a new 'bias from developer recruitment' factor that has unclear effect on slowdown.
Latest posts



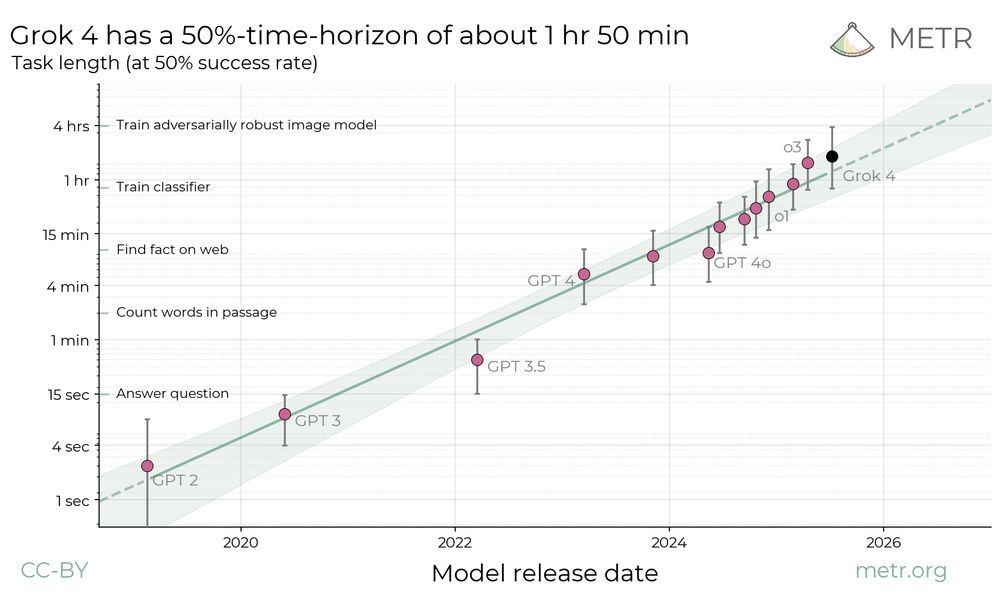
We have open-sourced anonymized data and core analysis code for our developer productivity RCT. The paper is also live on arXiv, with two new sections: One discussing alternative uncertainty estimation methods, and a new 'bias from developer recruitment' factor that has unclear effect on slowdown.
We ran a randomized controlled trial to see how much AI coding tools speed up experienced open-source developers. The results surprised us: Developers thought they were 20% faster with AI tools, but they were actually 19% slower when they had access to AI than when they didn't.
